14.2 协程间的信道
14.2.1 概念
在第一个例子中,协程是独立执行的,他们之间没有通信。他们必须通信才会变得更有用:彼此之间发送和接收信息并且协调/同步他们的工作。协程可以使用共享变量来通信,但是很不提倡这样做,因为这种方式给所有的共享内存的多线程都带来了困难。
而 Go 有一种特殊的类型,通道(channel),就像一个可以用于发送类型化数据的管道,由其负责协程之间的通信,从而避开所有由共享内存导致的陷阱;这种通过通道进行通信的方式保证了同步性。数据在通道中进行传递:在任何给定时间,一个数据被设计为只有一个协程可以对其访问,所以不会发生数据竞争。 数据的所有权(可以读写数据的能力)也因此被传递。
工厂的传送带是个很有用的例子。一个机器(生产者协程)在传送带上放置物品,另外一个机器(消费者协程)拿到物品并打包。
通道服务于通信的两个目的:值的交换,同步的,保证了两个计算(协程)任何时候都是可知状态。
通常使用这样的格式来声明通道:var identifier chan datatype
未初始化的通道的值是 nil。
所以通道只能传输一种类型的数据,比如 chan int 或者 chan string,所有的类型都可以用于通道,空接口 interface{} 也可以,甚至可以(有时非常有用)创建通道的通道。
通道实际上是类型化消息的队列:使数据得以传输。它是先进先出(FIFO) 的结构所以可以保证发送给他们的元素的顺序(有些人知道,通道可以比作 Unix shells 中的双向管道 (two-way pipe) )。通道也是引用类型,所以我们使用 make() 函数来给它分配内存。这里先声明了一个字符串通道 ch1,然后创建了它(实例化):
var ch1 chan string
ch1 = make(chan string)
当然可以更短: ch1 := make(chan string)。
这里我们构建一个 int 通道的通道: chanOfChans := make(chan chan int)。
或者函数通道:funcChan := make(chan func())(相关示例请看第 14.17 节)。
所以通道是第一类对象:可以存储在变量中,作为函数的参数传递,从函数返回以及通过通道发送它们自身。另外它们是类型化的,允许类型检查,比如尝试使用整数通道发送一个指针。
14.2.2 通信操作符 <-
这个操作符直观的标示了数据的传输:信息按照箭头的方向流动。
流向通道(发送)
ch <- int1 表示:用通道 ch 发送变量 int1(双目运算符,中缀 = 发送)
从通道流出(接收),三种方式:
int2 = <- ch 表示:变量 int2 从通道 ch(一元运算的前缀操作符,前缀 = 接收)接收数据(获取新值);假设 int2 已经声明过了,如果没有的话可以写成:int2 := <- ch。
<- ch 可以单独调用获取通道的(下一个)值,当前值会被丢弃,但是可以用来验证,所以以下代码是合法的:
if <- ch != 1000{
...
}
同一个操作符 <- 既用于发送也用于接收,但 Go 会根据操作对象弄明白该干什么 。虽非强制要求,但为了可读性通道的命名通常以 ch 开头或者包含 chan 。通道的发送和接收都是原子操作:它们总是互不干扰地完成。下面的示例展示了通信操作符的使用。
示例 14.2-goroutine2.go
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan string)
go sendData(ch)
go getData(ch)
time.Sleep(1e9)
}
func sendData(ch chan string) {
ch <- "Washington"
ch <- "Tripoli"
ch <- "London"
ch <- "Beijing"
ch <- "Tokyo"
}
func getData(ch chan string) {
var input string
// time.Sleep(2e9)
for {
input = <-ch
fmt.Printf("%s ", input)
}
}
输出:
Washington Tripoli London Beijing tokyo
main() 函数中启动了两个协程:sendData() 通过通道 ch 发送了 5 个字符串,getData() 按顺序接收它们并打印出来。
如果 2 个协程需要通信,你必须给他们同一个通道作为参数才行。
尝试一下如果注释掉 time.Sleep(1e9) 会如何。
我们发现协程之间的同步非常重要:
main()等待了 1 秒让两个协程完成,如果不这样,sendData()就没有机会输出。getData()使用了无限循环:它随着sendData()的发送完成和ch变空也结束了。- 如果我们移除一个或所有
go关键字,程序无法运行,Go 运行时会抛出 panic:
---- Error run E:/Go/Goboek/code examples/chapter 14/goroutine2.exe with code Crashed ---- Program exited with code -2147483645: panic: all goroutines are asleep-deadlock!
为什么会这样?运行时 (runtime) 会检查所有的协程(像本例中只有一个)是否在等待着什么东西(可从某个通道读取或者写入某个通道),这意味着程序将无法继续执行。这是死锁 (deadlock) 的一种形式,而运行时 (runtime) 可以为我们检测到这种情况。
注意:不要使用打印状态来表明通道的发送和接收顺序:由于打印状态和通道实际发生读写的时间延迟会导致和真实发生的顺序不同。
练习 14.4:解释一下为什么如果在函数 getData() 的一开始插入 time.Sleep(2e9),不会出现错误但也没有输出呢。
14.2.3 通道阻塞
默认情况下,通信是同步且无缓冲的:在有接受者接收数据之前,发送不会结束。可以想象一个无缓冲的通道在没有空间来保存数据的时候:必须要一个接收者准备好接收通道的数据然后发送者可以直接把数据发送给接收者。所以通道的发送/接收操作在对方准备好之前是阻塞的:
1)对于同一个通道,发送操作(协程或者函数中的),在接收者准备好之前是阻塞的:如果 ch 中的数据无人接收,就无法再给通道传入其他数据:新的输入无法在通道非空的情况下传入。所以发送操作会等待 ch 再次变为可用状态:就是通道值被接收时(可以传入变量)。
2)对于同一个通道,接收操作是阻塞的(协程或函数中的),直到发送者可用:如果通道中没有数据,接收者就阻塞了。
尽管这看上去是非常严格的约束,实际在大部分情况下工作的很不错。
程序 channel_block.go 验证了以上理论,一个协程在无限循环中给通道发送整数数据。不过因为没有接收者,只输出了一个数字 0。
示例 14.3-channel_block.go
package main
import "fmt"
func main() {
ch1 := make(chan int)
go pump(ch1) // pump hangs
fmt.Println(<-ch1) // prints only 0
}
func pump(ch chan int) {
for i := 0; ; i++ {
ch <- i
}
}
输出:
0
pump() 函数为通道提供数值,也被叫做生产者。
为通道解除阻塞定义了 suck() 函数来在无限循环中读取通道,参见示例 14.4-channel_block2.go:
func suck(ch chan int) {
for {
fmt.Println(<-ch)
}
}
在 main() 中使用协程开始它:
go pump(ch1)
go suck(ch1)
time.Sleep(1e9)
给程序 1 秒的时间来运行:输出了上万个整数。
练习 14.1:channel_block3.go:写一个通道证明它的阻塞性,开启一个协程接收通道的数据,持续 15 秒,然后给通道放入一个值。在不同的阶段打印消息并观察输出。
14.2.4 通过一个(或多个)通道交换数据进行协程同步。
通信是一种同步形式:通过通道,两个协程在通信(协程会合)中某刻同步交换数据。无缓冲通道成为了多个协程同步的完美工具。
甚至可以在通道两端互相阻塞对方,形成了叫做死锁的状态。Go 运行时会检查并 panic(),停止程序。死锁几乎完全是由糟糕的设计导致的。
无缓冲通道会被阻塞。设计无阻塞的程序可以避免这种情况,或者使用带缓冲的通道。
练习 14.2: blocking.go
解释为什么下边这个程序会导致 panic:所有的协程都休眠了 - 死锁!
package main
import (
"fmt"
)
func f1(in chan int) {
fmt.Println(<-in)
}
func main() {
out := make(chan int)
out <- 2
go f1(out)
}
14.2.5 同步通道-使用带缓冲的通道
一个无缓冲通道只能包含 1 个元素,有时显得很局限。我们给通道提供了一个缓存,可以在扩展的 make 命令中设置它的容量,如下:
buf := 100
ch1 := make(chan string, buf)
buf 是通道可以同时容纳的元素(这里是 string)个数
在缓冲满载(缓冲被全部使用)之前,给一个带缓冲的通道发送数据是不会阻塞的,而从通道读取数据也不会阻塞,直到缓冲空了。
缓冲容量和类型无关,所以可以(尽管可能导致危险)给一些通道设置不同的容量,只要他们拥有同样的元素类型。内置的 cap() 函数可以返回缓冲区的容量。
如果容量大于 0,通道就是异步的了:缓冲满载(发送)或变空(接收)之前通信不会阻塞,元素会按照发送的顺序被接收。如果容量是 0 或者未设置,通信仅在收发双方准备好的情况下才可以成功。
同步:ch :=make(chan type, value)
value == 0 -> synchronous, unbuffered (阻塞)value > 0 -> asynchronous, buffered(非阻塞)取决于value元素
若使用通道的缓冲,你的程序会在“请求”激增的时候表现更好:更具弹性,专业术语叫:更具有伸缩性(scalable)。在设计算法时首先考虑使用无缓冲通道,只在不确定的情况下使用缓冲。
练习 14.3:channel_buffer.go:给 channel_block3.go 的通道增加缓冲并观察输出有何不同。
14.2.6 协程中用通道输出结果
为了知道计算何时完成,可以通过信道回报。在例子 go sum(bigArray) 中,要这样写:
ch := make(chan int)
go sum(bigArray, ch) // bigArray puts the calculated sum on ch
// .. do something else for a while
sum := <- ch // wait for, and retrieve the sum
也可以使用通道来达到同步的目的,这个很有效的用法在传统计算机中称为信号量 (semaphore)。或者换个方式:通过通道发送信号告知处理已经完成(在协程中)。
在其他协程运行时让 main 程序无限阻塞的通常做法是在 main() 函数的最后放置一个 select {}。
也可以使用通道让 main 程序等待协程完成,就是所谓的信号量模式,我们会在接下来的部分讨论。
14.2.7 信号量模式
下边的片段阐明:协程通过在通道 ch 中放置一个值来处理结束的信号。main() 协程等待 <-ch 直到从中获取到值。
我们期望从这个通道中获取返回的结果,像这样:
func compute(ch chan int){
ch <- someComputation() // when it completes, signal on the channel.
}
func main(){
ch := make(chan int) // allocate a channel.
go compute(ch) // start something in a goroutines
doSomethingElseForAWhile()
result := <- ch
}
这个信号也可以是其他的,不返回结果,比如下面这个协程中的匿名函数 (lambda) 协程:
ch := make(chan int)
go func(){
// doSomething
ch <- 1 // Send a signal; value does not matter
}()
doSomethingElseForAWhile()
<- ch // Wait for goroutine to finish; discard sent value.
或者等待两个协程完成,每一个都会对切片 s 的一部分进行排序,片段如下:
done := make(chan bool)
// doSort is a lambda function, so a closure which knows the channel done:
doSort := func(s []int){
sort(s)
done <- true
}
i := pivot(s)
go doSort(s[:i])
go doSort(s[i:])
<-done
<-done
下边的代码,用完整的信号量模式对长度为 N 的 float64 切片进行了 N 个 doSomething() 计算并同时完成,通道 sem 分配了相同的长度(且包含空接口类型的元素),待所有的计算都完成后,发送信号(通过放入值)。在循环中从通道 sem 不停的接收数据来等待所有的协程完成。
type Empty interface {}
var empty Empty
...
data := make([]float64, N)
res := make([]float64, N)
sem := make(chan Empty, N)
...
for i, xi := range data {
go func (i int, xi float64) {
res[i] = doSomething(i, xi)
sem <- empty
} (i, xi)
}
// wait for goroutines to finish
for i := 0; i < N; i++ { <-sem }
注意上述代码中闭合函数的用法:i、xi 都是作为参数传入闭合函数的,这一做法使得每个协程(译者注:在其启动时)获得一份 i 和 xi 的单独拷贝,从而向闭合函数内部屏蔽了外层循环中的 i 和 xi 变量;否则,for 循环的下一次迭代会更新所有协程中 i 和 xi 的值。另一方面,切片 res 没有传入闭合函数,因为协程不需要 res 的单独拷贝。切片 res 也在闭合函数中但并不是参数。
14.2.8 实现并行的 for 循环
在上一部分章节 14.2.7 的代码片段中:for 循环的每一个迭代是并行完成的:
for i, v := range data {
go func (i int, v float64) {
doSomething(i, v)
...
} (i, v)
}
在 for 循环中并行计算迭代可能带来很好的性能提升。不过所有的迭代都必须是独立完成的。有些语言比如 Fortress 或者其他并行框架以不同的结构实现了这种方式,在 Go 中用协程实现起来非常容易:
14.2.9 用带缓冲通道实现一个信号量
信号量是实现互斥锁(排外锁)常见的同步机制,限制对资源的访问,解决读写问题,比如没有实现信号量的 sync 的 Go 包,使用带缓冲的通道可以轻松实现:
- 带缓冲通道的容量和要同步的资源容量相同
- 通道的长度(当前存放的元素个数)与当前资源被使用的数量相同
- 容量减去通道的长度就是未处理的资源个数(标准信号量的整数值)
不用管通道中存放的是什么,只关注长度;因此我们创建了一个长度可变但容量为 0(字节)的通道:
type Empty interface {}
type semaphore chan Empty
将可用资源的数量 N 来初始化信号量 semaphore:sem = make(semaphore, N)
然后直接对信号量进行操作:
// acquire n resources
func (s semaphore) P(n int) {
e := new(Empty)
for i := 0; i < n; i++ {
s <- e
}
}
// release n resources
func (s semaphore) V(n int) {
for i:= 0; i < n; i++{
<- s
}
}
可以用来实现一个互斥的例子:
/* mutexes */
func (s semaphore) Lock() {
s.P(1)
}
func (s semaphore) Unlock(){
s.V(1)
}
/* signal-wait */
func (s semaphore) Wait(n int) {
s.P(n)
}
func (s semaphore) Signal() {
s.V(1)
}
练习 14.5:gosum.go:用这种习惯用法写一个程序,开启一个协程来计算 2 个整数的和并等待计算结果并打印出来。
练习 14.6:producer_consumer.go:用这种习惯用法写一个程序,有两个协程,第一个提供数字 0,10,20,...,90 并将他们放入通道,第二个协程从通道中读取并打印。main() 等待两个协程完成后再结束。
习惯用法:通道工厂模式
编程中常见的另外一种模式如下:不将通道作为参数传递给协程,而用函数来生成一个通道并返回(工厂角色);函数内有个匿名函数被协程调用。
在 channel_block2.go 加入这种模式便有了示例 14.5-channel_idiom.go:
package main
import (
"fmt"
"time"
)
func main() {
stream := pump()
go suck(stream)
time.Sleep(1e9)
}
func pump() chan int {
ch := make(chan int)
go func() {
for i := 0; ; i++ {
ch <- i
}
}()
return ch
}
func suck(ch chan int) {
for {
fmt.Println(<-ch)
}
}
14.2.10 给通道使用 for 循环
for 循环的 range 语句可以用在通道 ch 上,便可以从通道中获取值,像这样:
for v := range ch {
fmt.Printf("The value is %v\n", v)
}
它从指定通道中读取数据直到通道关闭,才继续执行下边的代码。很明显,另外一个协程必须写入 ch(不然代码就阻塞在 for 循环了),而且必须在写入完成后才关闭。suck() 函数可以这样写,且在协程中调用这个动作,程序变成了这样:
示例 14.6-channel_idiom2.go:
package main
import (
"fmt"
"time"
)
func main() {
suck(pump())
time.Sleep(1e9)
}
func pump() chan int {
ch := make(chan int)
go func() {
for i := 0; ; i++ {
ch <- i
}
}()
return ch
}
func suck(ch chan int) {
go func() {
for v := range ch {
fmt.Println(v)
}
}()
}
习惯用法:通道迭代器模式
这个模式用到了后边 14.6 章示例 producer_consumer.go 的生产者-消费者模式。通常,需要从包含了地址索引字段 items 的容器给通道填入元素。为容器的类型定义一个方法 Iter(),返回一个只读的通道(参见第 14.2.11 节)items,如下:
func (c *container) Iter () <- chan item {
ch := make(chan item)
go func () {
for i:= 0; i < c.Len(); i++{ // or use a for-range loop
ch <- c.items[i]
}
} ()
return ch
}
在协程里,一个 for 循环迭代容器 c 中的元素(对于树或图的算法,这种简单的 for 循环可以替换为深度优先搜索)。
调用这个方法的代码可以这样迭代容器:
for x := range container.Iter() { ... }
其运行在自己启动的协程中,所以上边的迭代用到了一个通道和两个协程(可能运行在不同的线程上)。 这样我们就有了一个典型的生产者-消费者模式。如果在程序结束之前,向通道写值的协程未完成工作,则这个协程不会被垃圾回收;这是设计使然。这种看起来并不符合预期的行为正是由通道这种线程安全的通信方式所导致的。如此一来,一个协程为了写入一个永远无人读取的通道而被挂起就成了一个 bug ,而并非你预想中的那样被悄悄回收掉 (garbage-collected) 了。
习惯用法:生产者消费者模式
假设你有 Produce() 函数来产生 Consume() 函数需要的值。它们都可以运行在独立的协程中,生产者在通道中放入给消费者读取的值。整个处理过程可以替换为无限循环:
for {
Consume(Produce())
}
14.2.11 通道的方向
通道类型可以用注解来表示它只发送或者只接收:
var send_only chan<- int // channel can only receive data
var recv_only <-chan int // channel can only send data
只接收的通道 (<-chan T) 无法关闭,因为关闭通道是发送者用来表示不再给通道发送值了,所以对只接收通道是没有意义的。通道创建的时候都是双向的,但也可以分配给有方向的通道变量,就像以下代码:
var c = make(chan int) // bidirectional
go source(c)
go sink(c)
func source(ch chan<- int){
for { ch <- 1 }
}
func sink(ch <-chan int) {
for { <-ch }
}
习惯用法:管道和选择器模式
更具体的例子还有协程处理它从通道接收的数据并发送给输出通道:
sendChan := make(chan int)
receiveChan := make(chan string)
go processChannel(sendChan, receiveChan)
func processChannel(in <-chan int, out chan<- string) {
for inValue := range in {
result := ... /// processing inValue
out <- result
}
}
通过使用方向注解来限制协程对通道的操作。
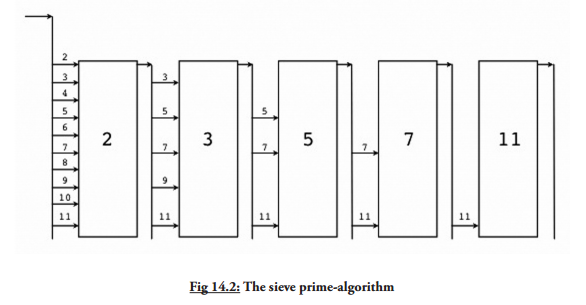
这里有一个来自 Go 指导的很赞的例子,打印了输出的素数,使用选择器(‘筛’)作为它的算法。每个 prime 都有一个选择器,如下图:
版本1:示例 14.7-sieve1.go
// Copyright 2009 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.package main
package main
import "fmt"
// Send the sequence 2, 3, 4, ... to channel 'ch'.
func generate(ch chan int) {
for i := 2; ; i++ {
ch <- i // Send 'i' to channel 'ch'.
}
}
// Copy the values from channel 'in' to channel 'out',
// removing those divisible by 'prime'.
func filter(in, out chan int, prime int) {
for {
i := <-in // Receive value of new variable 'i' from 'in'.
if i%prime != 0 {
out <- i // Send 'i' to channel 'out'.
}
}
}
// The prime sieve: Daisy-chain filter processes together.
func main() {
ch := make(chan int) // Create a new channel.
go generate(ch) // Start generate() as a goroutine.
for {
prime := <-ch
fmt.Print(prime, " ")
ch1 := make(chan int)
go filter(ch, ch1, prime)
ch = ch1
}
}
协程 filter(in, out chan int, prime int) 拷贝整数到输出通道,丢弃掉可以被 prime 整除的数字。然后每个 prime 又开启了一个新的协程,生成器和选择器并发请求。
输出:
2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97 101
103 107 109 113 127 131 137 139 149 151 157 163 167 173 179 181 191 193 197 199 211 223
227 229 233 239 241 251 257 263 269 271 277 281 283 293 307 311 313 317 331 337 347 349
353 359 367 373 379 383 389 397 401 409 419 421 431 433 439 443 449 457 461 463 467 479
487 491 499 503 509 521 523 541 547 557 563 569 571 577 587 593 599 601 607 613 617 619
631 641 643 647 653 659 661 673 677 683 691 701 709 719 727 733 739 743 751 757 761 769
773 787 797 809 811 821 823 827 829 839 853 857 859 863 877 881 883 887 907 911 919 929
937 941 947 953 967 971 977 983 991 997 1009 1013...
第二个版本引入了上边的习惯用法:函数 sieve()、generate() 和 filter() 都是工厂;它们创建通道并返回,而且使用了协程的 lambda 函数。main() 函数现在短小清晰:它调用 sieve() 返回了包含素数的通道,然后通过 fmt.Println(<-primes) 打印出来。
版本2:示例 14.8-sieve2.go
// Copyright 2009 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
package main
import (
"fmt"
)
// Send the sequence 2, 3, 4, ... to returned channel
func generate() chan int {
ch := make(chan int)
go func() {
for i := 2; ; i++ {
ch <- i
}
}()
return ch
}
// Filter out input values divisible by 'prime', send rest to returned channel
func filter(in chan int, prime int) chan int {
out := make(chan int)
go func() {
for {
if i := <-in; i%prime != 0 {
out <- i
}
}
}()
return out
}
func sieve() chan int {
out := make(chan int)
go func() {
ch := generate()
for {
prime := <-ch
ch = filter(ch, prime)
out <- prime
}
}()
return out
}
func main() {
primes := sieve()
for {
fmt.Println(<-primes)
}
}
链接
- 目录
- 上一节:并发、并行和协程
- 下一节:协程同步:关闭通道-测试阻塞的通道